Default prediction with Zenml
Default prediction with Zenml
What we built
A simple ML pipeline that helps to perform loan default prediction. The actual tasks carried out by the pipeline include:
- dataset preparation
- feature engineering
- model training and retraining
- model serving
The submission also includes a GUI that allows users to:
- run batch inference
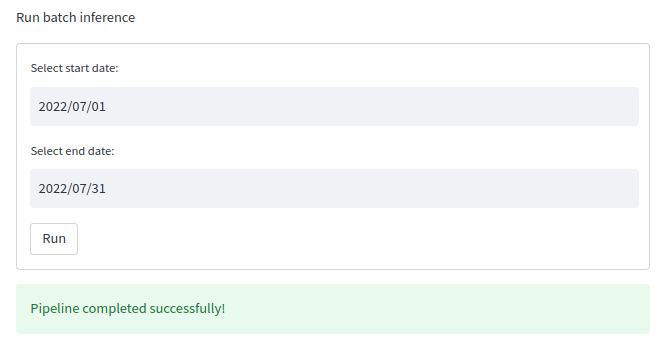
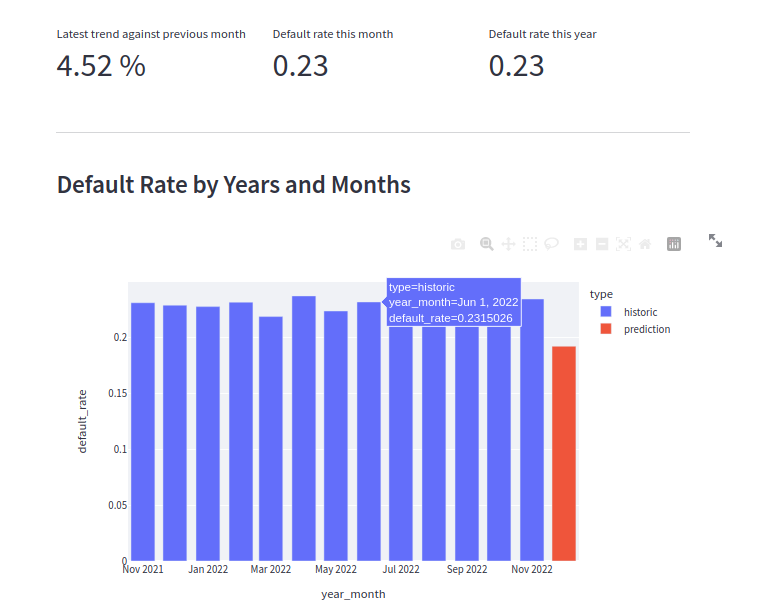
- view business reports (outcome of prediction)
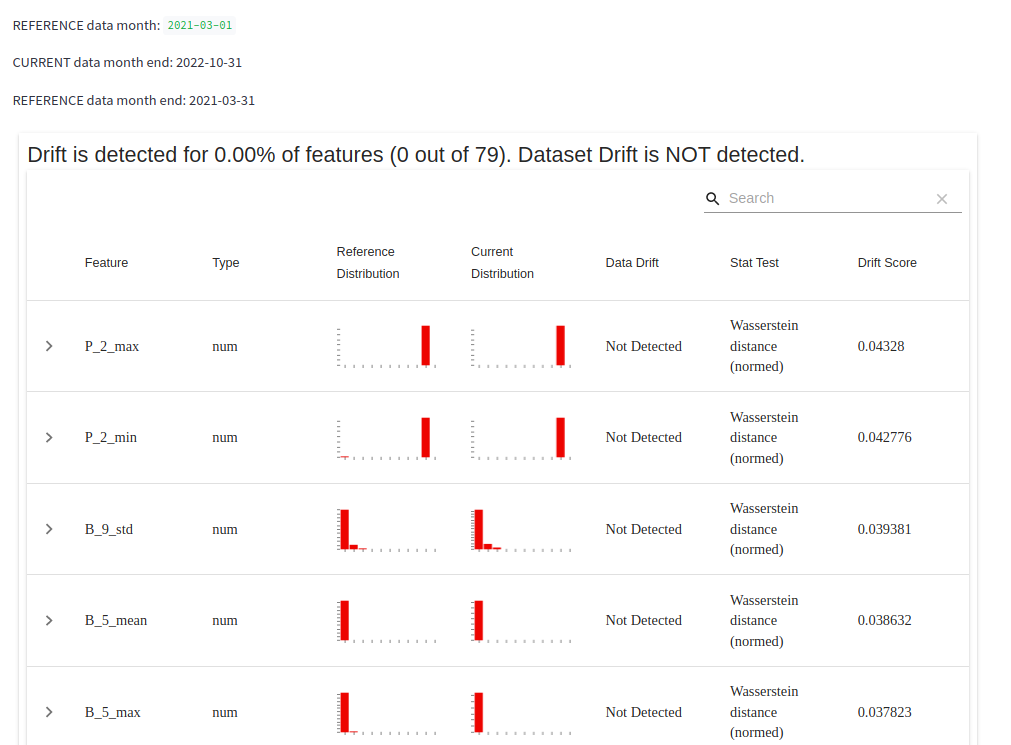
- monitor for data drift
Why we chose this for our project to work on?
Our goal of participation is to learn Zenml. We began by exploring some public datasets and found the (AMEX Default Prediction dataset)[https://www.kaggle.com/competitions/amex-default-prediction/data], which contains borrowers’ 13-month profile data as learning features and the occurrence of a default event as the learning target. We modeled a binary classifier based on this dataset.
We decided that this use case would be interesting to work on as we have not seen a lot of MLOps use cases shared publicly from an industry like banking, that requires very strict compliance and high transparency (during auditing) in the areas of dataset preparation, model development, model evaluation (and interpretation) and more.
How we used ZenML to build out our pipeline?
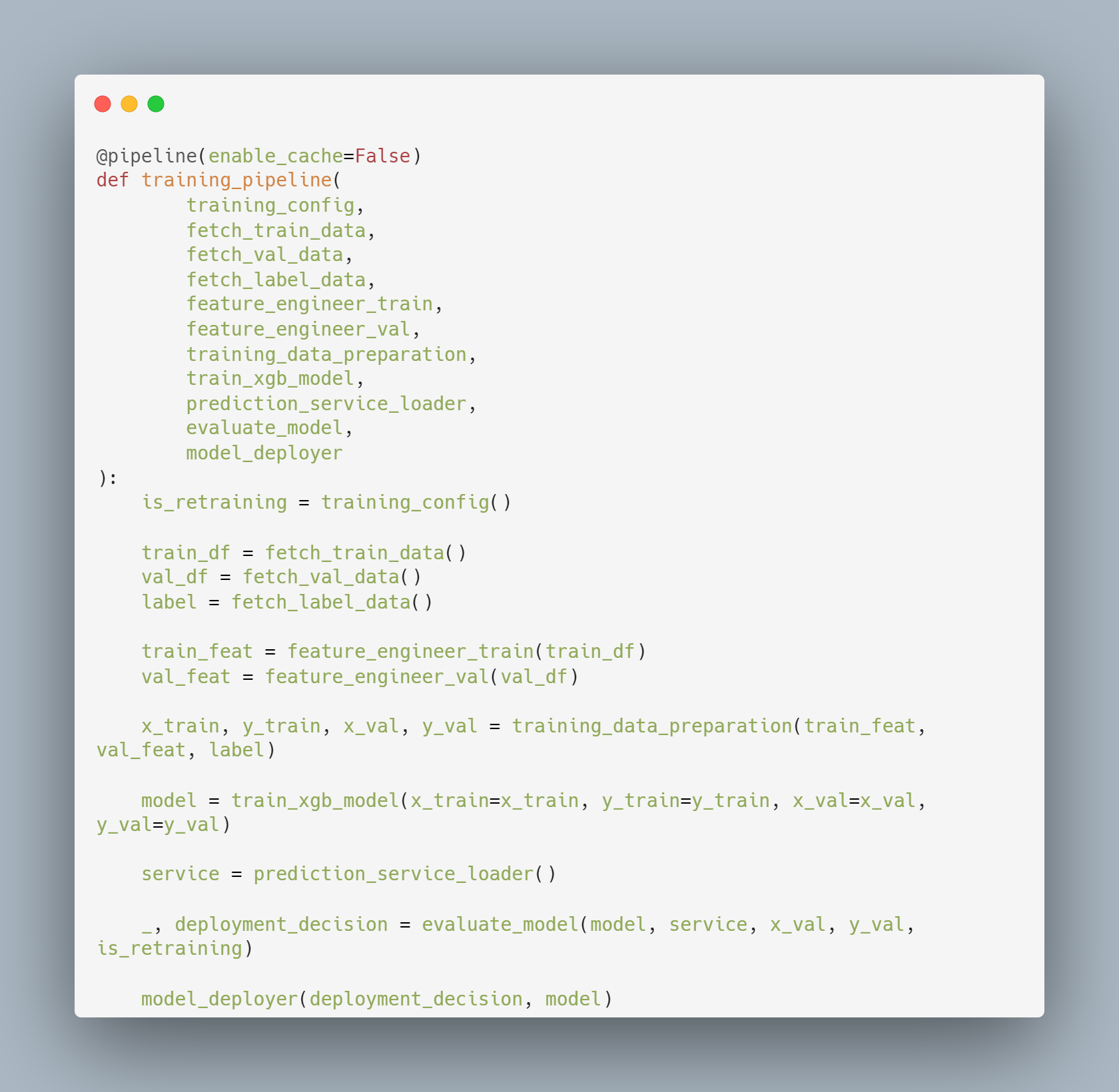
The first pipeline we created is the model training pipeline. The pipeline contains the following steps:
- create training config
- fetch training data
- fetch validation data
- fetch labels
- feature engineer training data
- feature engineer validation data
- training data preparation
- train an XGBoost model
- create a prediction service
- evaluate model and compare models to find the winning model
- deploy last best model (MLflow deployer)
We also attempted to build 2 slightly different inference pipelines to support 2 use cases:
- A batch inference pipeline that answers “how many borrowers will default their payment next month?”
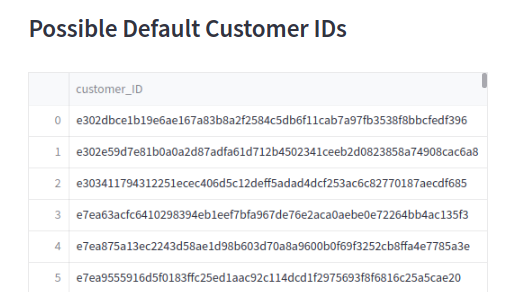
- single-customer inference pipeline to predict if a given customer id will fulfill their payment or not. These pipelines contain the following steps:
- fetch inference data
- feature engineer the inference data
- load prediction service
- make prediction with deployed model
- store predictions
What stack components we used and how we structured our code
We use the MLflow component in this submission. Despite using Evidently to perform drift detection, it was not integrated using Zenml’s component.
All the Zenml pipeline code are kept in the app folder, and we followed the common code structure used by Zenml users by writing all the pipelines in a ‘pipelines’ folder while the steps are kept in a ‘steps’ folder. Here’s an example of how we created the training pipeline using the individual steps:
Any demo or visual artifacts to showcase what we built
Run the launch.sh script in our project to use the GUI in your browser.